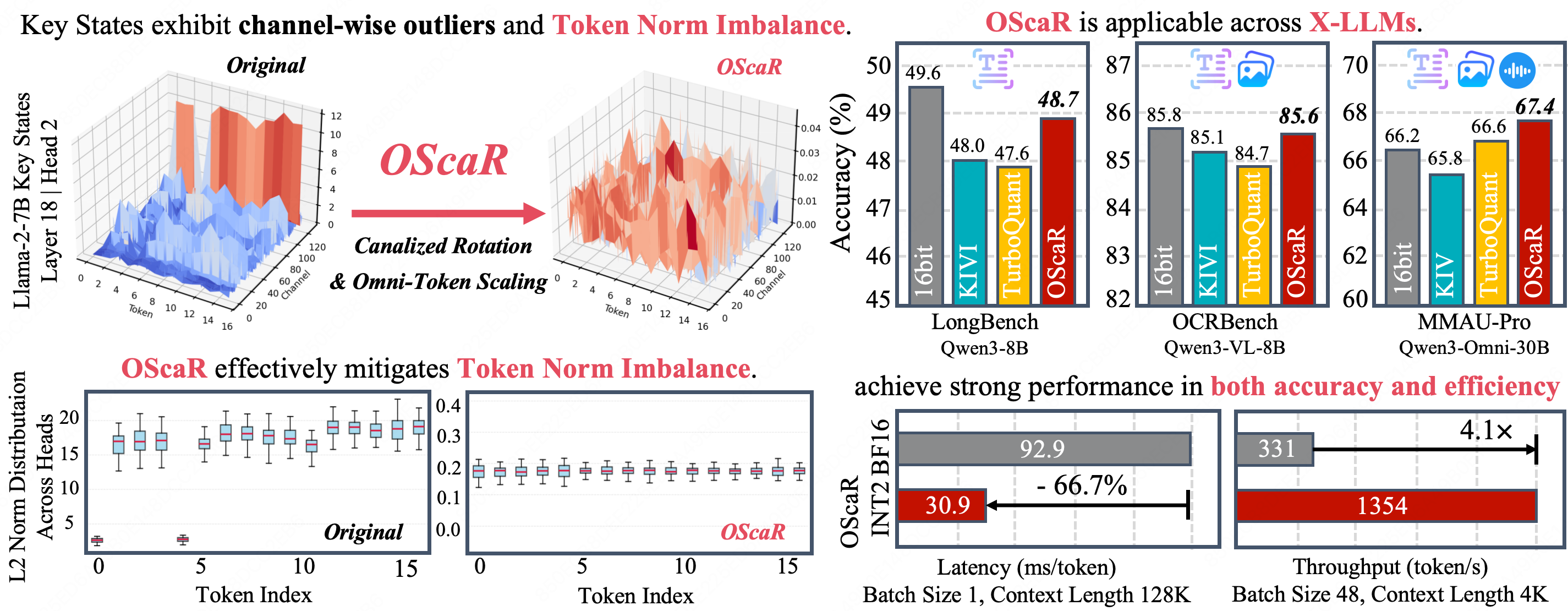
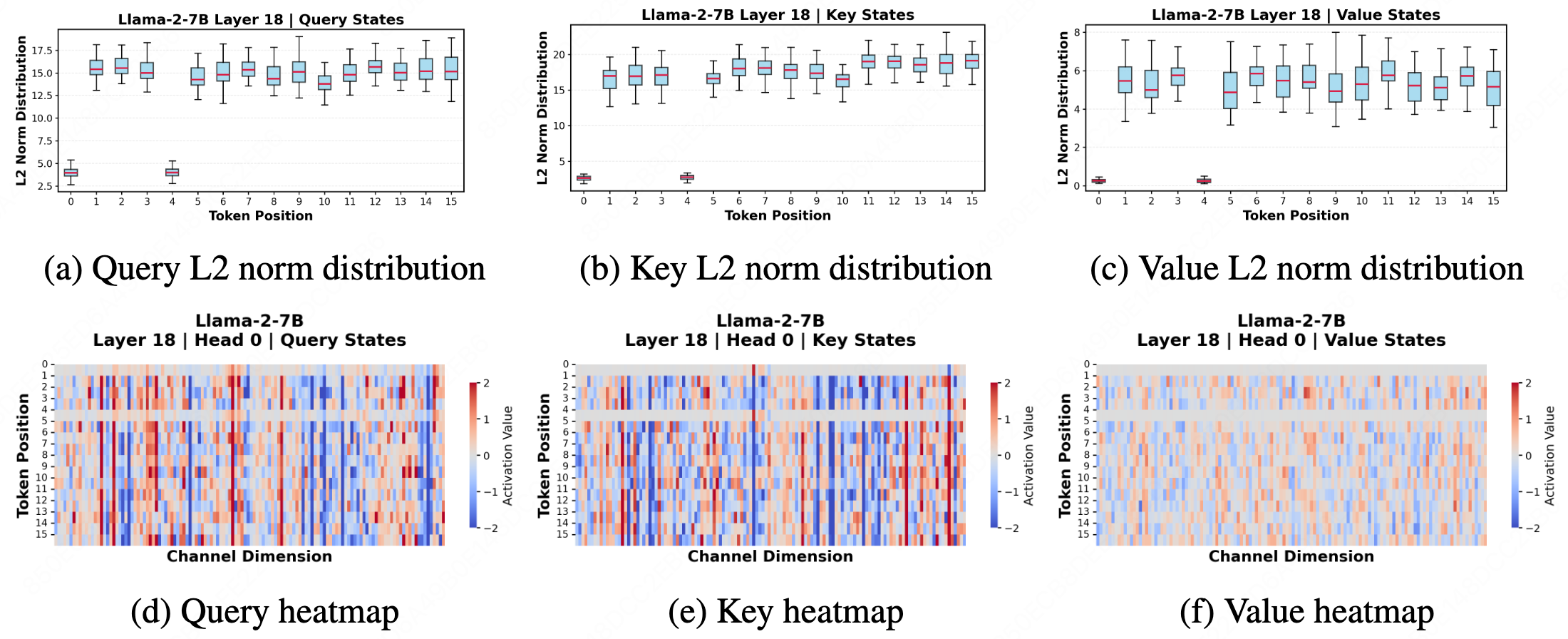
TNI Diagnosis
Pinpointing the structural bottleneck of per-channel quantization under extreme compression from both empirical and theoretical perspectives.
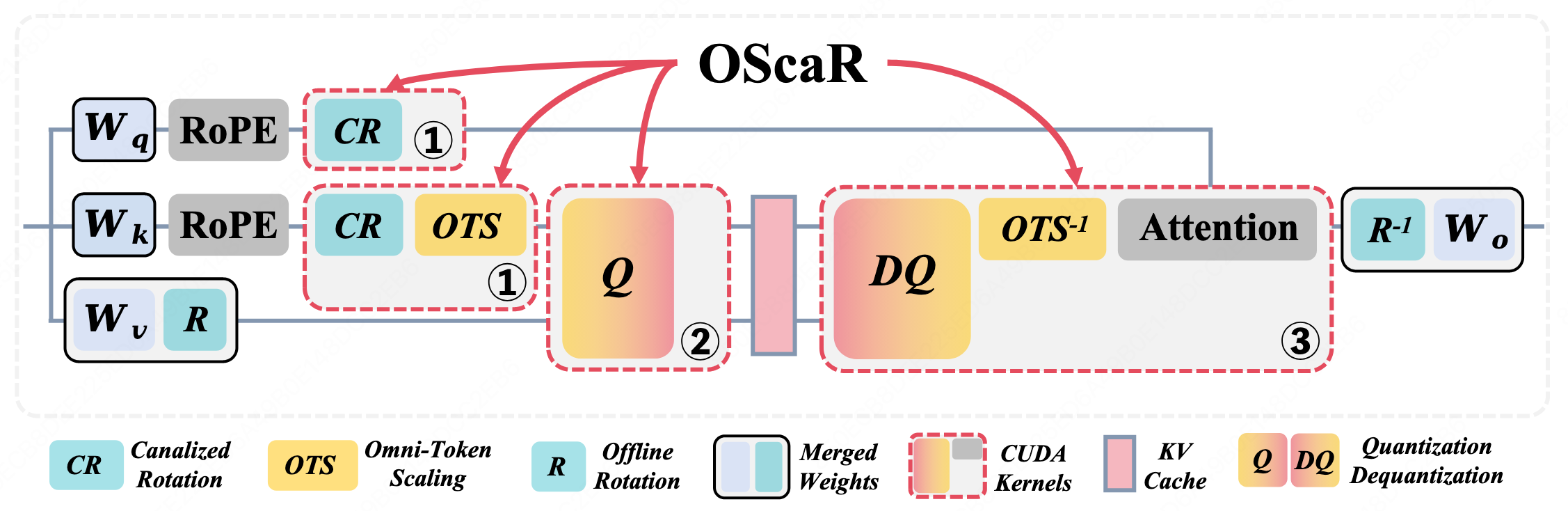
A lightweight KV cache compression framework for long-context reasoning and multi-modal intelligence. By leveraging Canalized Rotation + Omni-Token Scaling, OScaR mitigates Token Norm Imbalance (TNI) to achieve near-lossless INT2 quantization.
Pinpointing the structural bottleneck of per-channel quantization under extreme compression from both empirical and theoretical perspectives.
Only two steps: Rotation + Token Scaling — reducing complex pipeline dependencies.
BitDecoding + HadaCore + Tensor Core acceleration, redefining the Pareto frontier.
[Upcoming] vLLM & SGLang backend integration
Under active development — official support will be announced in future releases.
[2026-05-20] Paper on arXiv!
Our paper "OScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond" is now available on arXiv. Read it here →
[2026-05-19] Codebase released
Codebase and evaluation suite publicly released on GitHub.
The rapid advancement toward long-context reasoning and multi-modal intelligence has made KV cache memory footprint a dominant bottleneck. We revisit the inherent limitations of the established per-channel quantization paradigm and identify Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity.
Rather than relying on intricate pipelines, we follow the principle of Occam's Razor. We propose OScaR (Omni-Scaled Canalized Rotation), an accurate and lightweight KV cache compression framework for X-LLMs (text-only, multi-modal, and omni-modal LLMs).
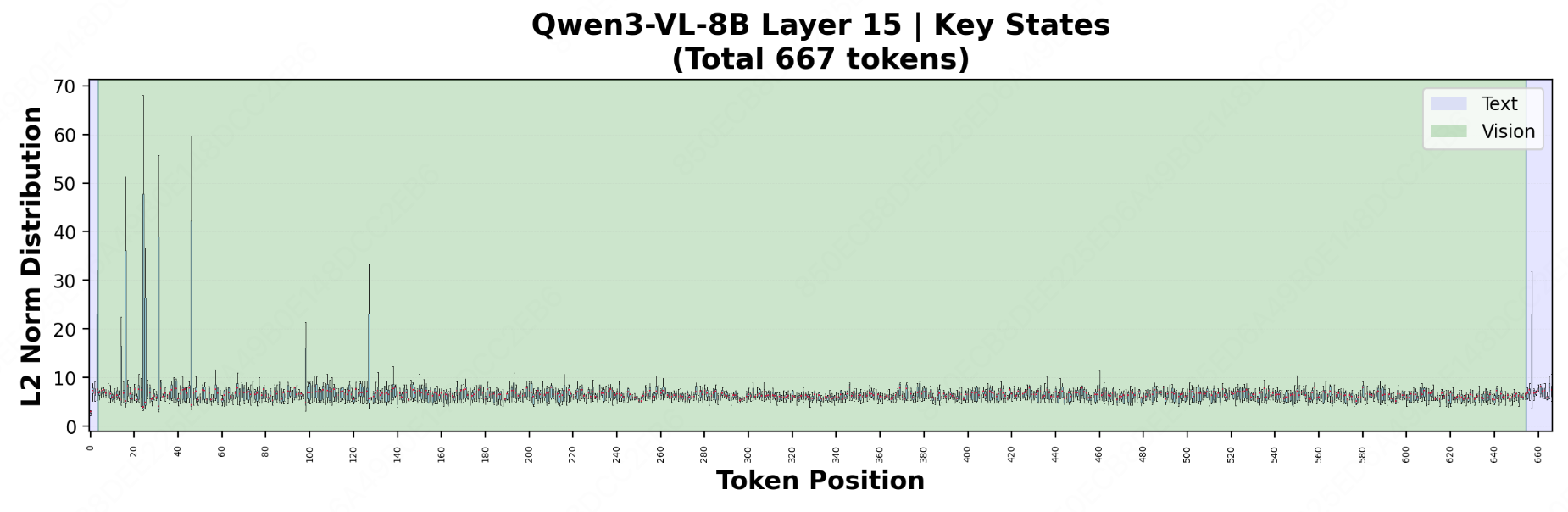
Token Norm Imbalance manifests differently across model types.
TNI is pervasive across X-LLMs. In text-only models, it manifests as low-norm outlier tokens, also known as Attention Sink tokens. In multi-modal settings, TNI exhibits more diverse forms, including large-norm outliers, significant inter-modality disparities, and broader norm variations.
Unveils Token Norm Imbalance as the structural bottleneck of per-channel quantization through both empirical and theoretical analysis.
Streamlined OScaR framework requiring only two essential operations — Canalized Rotation and Omni-Token Scaling, with no training or calibration overhead.
Delivers near-lossless INT2 quantization across diverse benchmarks while maintaining low computational complexity.
CUDA kernels built on BitDecoding and HadaCore with Tensor Core acceleration — achieving 3.0× speedup, 5.3× memory reduction, and 4.1× throughput increase vs. BF16 FlashDecoding-v2.
OScaR achieves the highest average accuracy among all 2-bit methods.
| Method | Llama-3.1-8B | Qwen3-8B |
|---|---|---|
| 16-bit Baseline | 41.70 | 49.56 |
| QuaRot (INT2) | 37.94 | 40.13 |
| RotateKV (INT2) | 37.98 | 42.95 |
| KIVI (INT2) | 39.84 | 47.95 |
| OTT (INT2) | 40.74 | 48.21 |
| TurboQuant+ (2.5-bit) | 40.03 | 47.56 |
| OScaR (INT2) | 41.75 | 48.74 |
Consistently outperforms other 2-bit methods across all models.
| Method | LLaVA-v1.6-7B | Qwen3-VL-8B | Qwen3-VL-4B |
|---|---|---|---|
| 16-bit Baseline | 536 | 858 | 852 |
| QuaRot (INT2) | 481 | 722 | 773 |
| RotateKV (INT2) | 473 | 754 | 638 |
| KIVI (INT2) | 488 | 851 | 813 |
| OTT (INT2) | 513 | 850 | 831 |
| TurboQuant+ (2.5-bit) | 501 | 847 | 828 |
| OScaR (INT2) | 519 | 856 | 838 |
Surpasses both baseline and all quantized methods across all dimensions.
| Method (Qwen3-Omni-30B-A3B) | Open-ended | Good Rate | AIF |
|---|---|---|---|
| 16-bit Baseline | 66.2 | 27.8 | 87.4 |
| KIVI (INT2) | 65.8 | 27.0 | 78.2 |
| OTT (INT2) | 65.8 | 26.9 | 83.9 |
| TurboQuant+ (2.5-bit) | 66.6 | 27.0 | 79.3 |
| OScaR (INT2) | 67.4 | 29.8 | 88.5 |
Detailed experimental setups and TurboQuant+ implementation details are available in the original paper.
Abstract and citation.
The rapid advancement toward long-context reasoning and multi-modal intelligence has made the memory footprint of the Key-Value (KV) cache a dominant memory bottleneck for efficient deployment...
The rapid advancement toward long-context reasoning and multi-modal intelligence has made the memory footprint of the Key-Value (KV) cache a dominant memory bottleneck for efficient deployment. While the established per-channel quantization effectively accommodates intrinsic channel-wise outliers in Key tensors, its efficacy diminishes under extreme compression. In this work, we revisit the inherent limitations of the per-channel quantization paradigm from both empirical and theoretical perspectives. Our analysis identifies Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity. We demonstrate that TNI systematically amplifies errors when shared quantization parameters are required to span token groups exhibiting substantial norm disparities. Instead of relying on intricate quantization pipelines (e.g., TurboQuant), we propose OScaR (Omni-Scaled Canalized Rotation), an accurate and lightweight KV cache compression framework for X-LLMs (i.e., text-only, multi-modal, and omni-modal LLMs). Advancing the per-channel paradigm, OScaR employs Canalized Rotation followed by Omni-Token Scaling to mitigate TNI-induced sequence-dimensional variance both effectively and efficiently, further supported by our optimized system design and CUDA kernels. Extensive evaluations across X-LLMs show that OScaR consistently outperforms existing methods and achieves near-lossless performance under INT2 quantization, establishing it as a robust, low-complexity, and universal framework that defines a new Pareto front. Compared with the BF16 FlashDecoding-v2 baseline, our OScaR implementation achieves a notable up to 3.0x speedup in decoding, reduces memory footprint by 5.3x, and increases throughput by 4.1x. The code for OScaR is publicly available at this https URL.
If you find OScaR useful, please cite our paper:
@article{su2026oscar,
title={OScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond},
author={Su, Zunhai and Yang, Rui and Zhang, Chao and Liu, Yaxiu and Zhang, Yifan and Wu, Wei and Xiong, Jing and Du, Dayou and Zhuang, Xialie and Qian, Yulei and Xie, Yuchen and Wu, Yik-Chung and Yang, Hongxia and Wong, Ngai},
journal={arXiv preprint arXiv:2605.19660},
year={2026}
}(Click copies BibTeX to your clipboard)
OScaR is inspired by many open-source libraries, including but not limited to BitDecoding, HadaCore, KIVI, and SGLang-FluentLLM.